Práce s daty


Modul nazýváme reporty a datové výstupy právě proto, že neslouží zdaleka jen k tvorbě PDF dokumentů (= reportů). Mnoho datových výstupů nemusí mít vůbec vizuální podobu, jsou tedy například určeny k získání různých informací ze studijní agendy. Novinkou oproti původnímu reportovacímu nástroji je možnost získání samotných zdrojových dat - tedy té podoby dat, ze které je pak v dalším kroku vytvořen samotný PDF soubor.
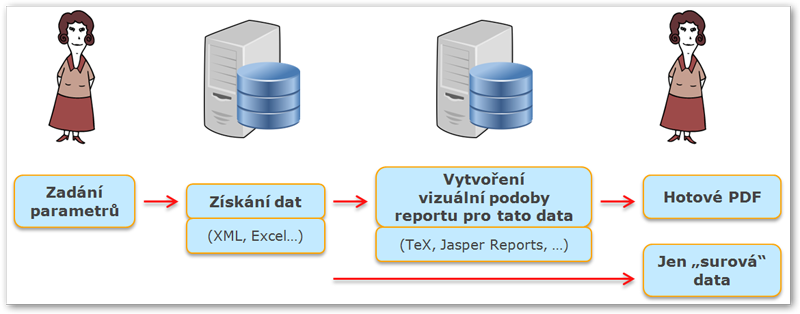
Obrázek 844. Základní princip fungování při volání reportu - možnost získat PDF či surová data běžným způsobem.
Tato možnost je implementována z několik důvodů. Vždy se může hodit získat ona surová data, z nichž je poté PDF dokument vytvořen. Zákazníkovi například nemusí vyhovovat podoba PDF dokumentu a má-li tu možnost, může si report v libovolném nástroji (existují jich desítky) vytvořit sám a napojit jej na námi poskytovaná data.
Data mohou být k dispozici nejen prostřednictvím uživatelského rozhraní na webu, ale jsou k dispozici i ve formě webových služeb (SOAP i REST), takže je možno je využít přímo například jiným informačním systémem.
Úprava dat, z nichž se tvoří report
Další z důvodů je umožnění uživateli zasáhnout do samotného procesu tvorby reportu, umožnit mu udělat „malé“ úpravy v datech a výsledný PDF dokument vytvořit až z těchto uživatelem upravených dat:
Tvorba vizuální podoby jakýchkoliv informací je vždy velmi subjektivní záležitost, zvláště u složitých dokumentů. Konkrétní počítačový nástroj se snaží vytvořit dokument co možná „nejlepší“, přičemž ale určení toho, co je „nejlepší“, je u různých uživatelů velmi rozdílné. Nástroje respektují typografická pravidla a optimalizují výslednou podobu dokumentu tak, aby byla pokud možno porušena co nejméně. Vždy se ale objeví malá část případů, kdy výsledný dokument uživateli z nějakého důvodu nevyhovuje. S tím je třeba dopředu počítat. Snažíme se, aby naprostá většina výstupů byla rozumná a vypadala „hezky“. Vždy se ale objeví situace, kdy toho není možné dosáhnout.
Výsledná podoba dokumentu je jendoznačně určena jeho vstupními daty. Představíme-li si, že si například vyučující pojmenuje předmět názvem sestávajícím z padesáti slov, systém TeX který následně sází Diploma Supplement pro studenta bude mít velký problém, aby se název vešel rozumně na určené místo. Další příkladem jsou jména a příjmení - naprostá většina studentů má jméno a příjmení tak nějak rozumně dlouhé a jsou tomu uzpůsobeny všemožné formuláře. Objeví se ale jeden cizinec ze sta, který má 7 křestních jmen a je třeba improvizovat - třeba vybrat jen to jedno hlavní, aby se jeho jméno vešlo třeba do formuláře pro potvrzení o studiu.
Z tohoto důvodu náš nový reportovací nástroj umožňuje uživateli vstoupit do jinak automatického procesu tvorby reportu a „uprostřed jej na chvíli přerušit“:
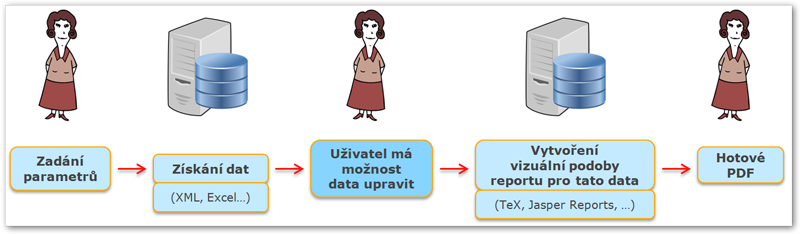
Obrázek 845. Možnost získat PDF vytvořené z dat, která předtím měl uživatel možnost upravit.
Vygenerování samotných dat: Uživatel si nechá vytvořit pouze surová data a ta si stáhne k sobě na počítač.
Úprava těchto dat: Uživatel data ručně upraví podle své potřeby - například zkrátí křestní jméno či název předmětu. Je možno udělat i větší úpravy, které samy o sobě mohou řešit mnoho situací, na které informační systém není stavěný. Například přidat do seznamu absolvovaných předmětů nějaký speciální předmět, který informační systém neeviduje či naopak odstranění něčeho, co na reportu mít nechceme. Vzhledem k tomu, že výroba následného PDF pracuje zcela a jen nad těmito daty, lze si představit poměrně široké spektrum možností. Je třeba nicméně podotknout, že se stále jedná o úpravy jednorázového a výjimečného charakteru.
Použití těchto dat k vytvoření reportu: Uživatel upravená data vrátí prostřednictvím webové aplikace do procesu. Reportovací nástroj vytvoří PDF na základě dat zaslaných uživatelem. Pozor, přestože pro export dat podporuje aplikace více formátů (např- JSON a další), pro import dat v tomto případě je podporovaný pouze formát XML!
V kapitole o ovládání aplikace je popsán přesný postup, jak zde popsaných možností docílit.